
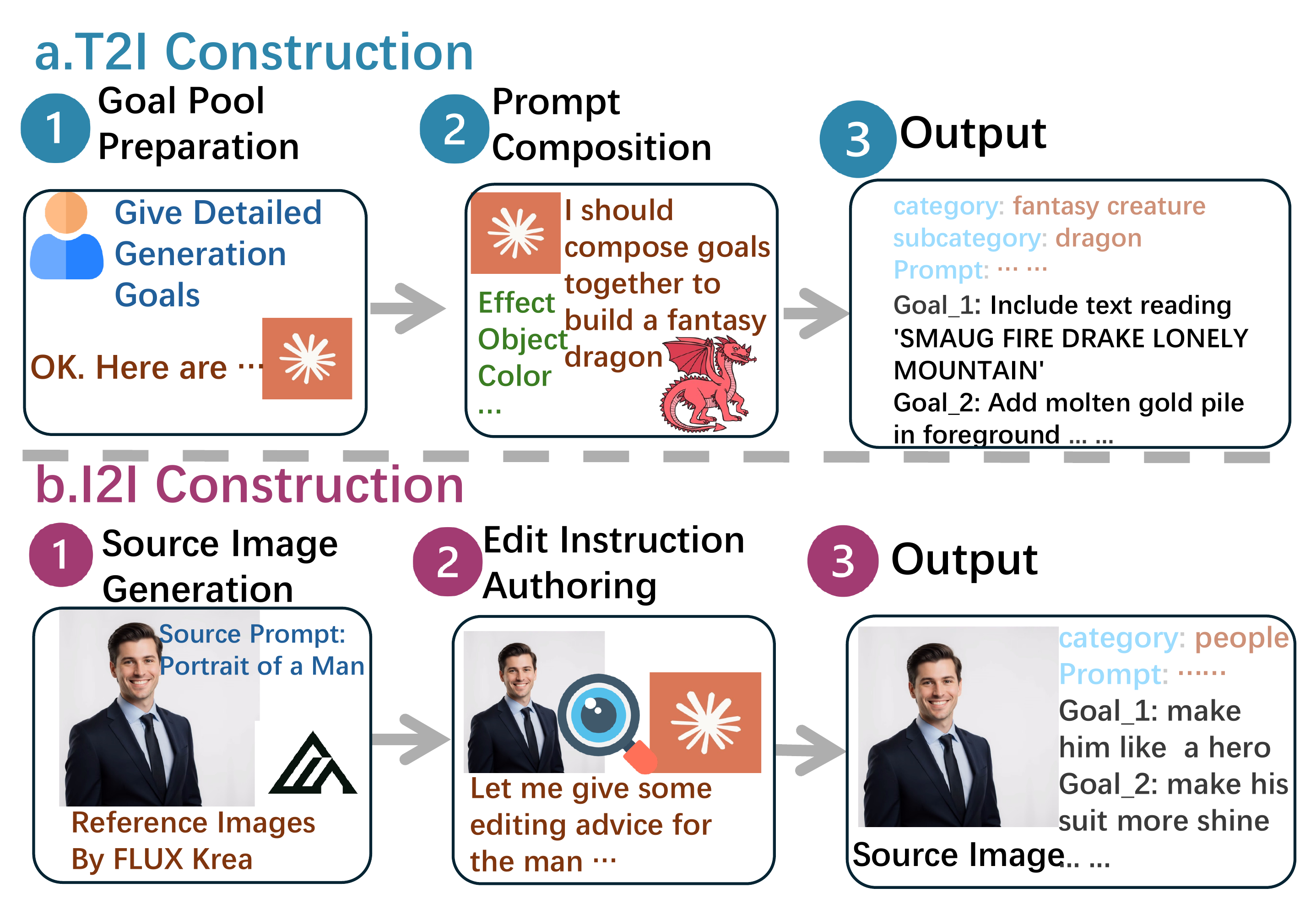
VisionDirector enables automatic step-by-step refinement for both Image Editing and Image Generation tasks, achieving superior multi-goal alignment compared to closed-source models.
VisionDirector enables automatic step-by-step refinement for both Image Editing and Image Generation tasks, achieving superior multi-goal alignment compared to closed-source models.
The field of visual content creation has progressed rapidly with the rise of diffusion models. However, professional image creation often relies on long, multi-goal instructions specifying global composition, local object placement, typography, and stylistic constraints. While modern diffusion models achieve strong visual fidelity, they frequently fail to satisfy such tightly coupled objectives.
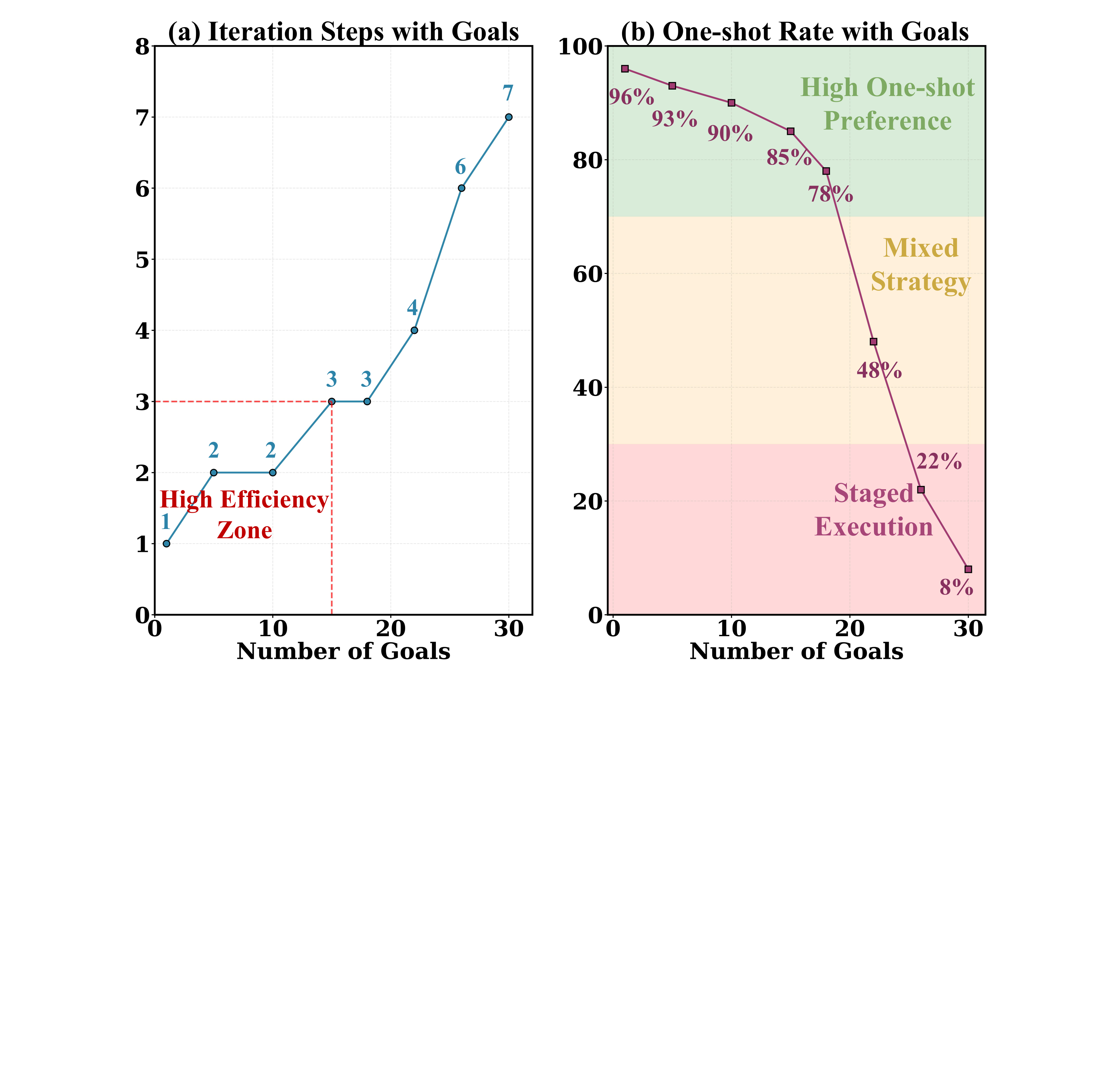
To systematically expose this gap, we introduce LongGoalBench (LGBench), a dual-modality benchmark comprising 2,000 tasks (1,000 T2I + 1,000 I2I) with over 29,000+ annotated goals and automated goal-level verification. LGBench stresses multi-attribute alignment rather than simple prompt fidelity, with each task requiring satisfaction of 10–23 quantitative goals.
We further propose VisionDirector, a training-free, vision-language guided closed-loop framework that decomposes long instructions into structured goals, dynamically plans generation or editing actions, and verifies goal satisfaction after each step—achieving 30% improvement on GenEval and 60% improvement on ComplexBench over state-of-the-art methods.
A director-style stress test for multi-goal image generation and editing
Goal Type Distribution:
| Benchmark | Modalities | Prompt Complexity | Goals per Task | Scale |
|---|---|---|---|---|
| LGBench (Ours) | T2I + I2I | Long-chain | 10–23 | 2,000 |
| DrawBench / VBench | T2I | Single sentence | 1 | 200–300 |
| TIFA / GenEval | T2I | Short + QA | 1–2 | 500–1000 |
| MagicBrush / EditEval | I2I | Short directive | Few | <500 |
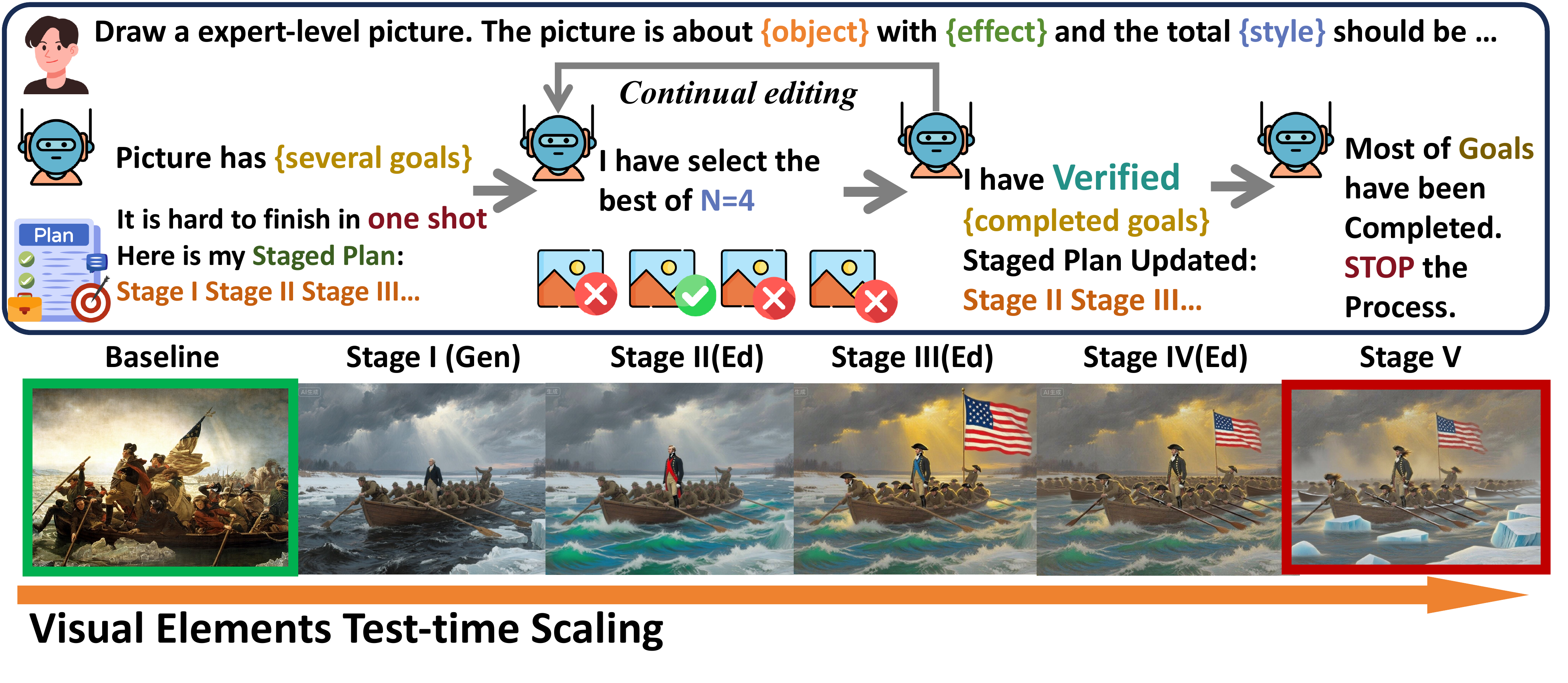
VisionDirector consistently improves multi-goal adherence on complex generation and editing tasks

Multi-stage editing with comparison against Qwen-Image, Seeddream, GPT-Image, and KONTEXT-MAX

High-fidelity generation with multi-goal alignment

Handling extremely detailed instructions: Multidimensional Ballroom, Quantum Archaeology Laboratory, Forest Cathedral


@misc{chu2025visiondirector,
title = {VisionDirector: Vision-Language Guided Closed-Loop Refinement for Generative Image Synthesis},
author = {Chu, Meng and Yang, Senqiao and Che, Haoxuan and Zhang, Suiyun and Zhang, Xichen and Yu, Shaozuo and Gui, Haokun and Rao, Zhefan and Tu, Dandan and Liu, Rui and Jia, Jiaya},
year = {2025},
eprint = {2512.19243},
archivePrefix= {arXiv},
primaryClass = {cs.CV}
}